2. SpeeDBee Synapseの概要
本章では、SpeeDBee Synapseの特徴、構成、運用までの流れについて説明します。
2.1 SpeeDBee Synapseの特徴#
SpeeDBee Synapseは、FAやIoTを構成する様々な機器(PLC等)よりデータを収集できます。 収集したデータをSpeeDBee Synapseの各種機能を利用する事により、変換や分析、そして、他システムとのデータ連携が可能です。 これによりデータ収集からデータ活用までを実現するシステムを構築できます。
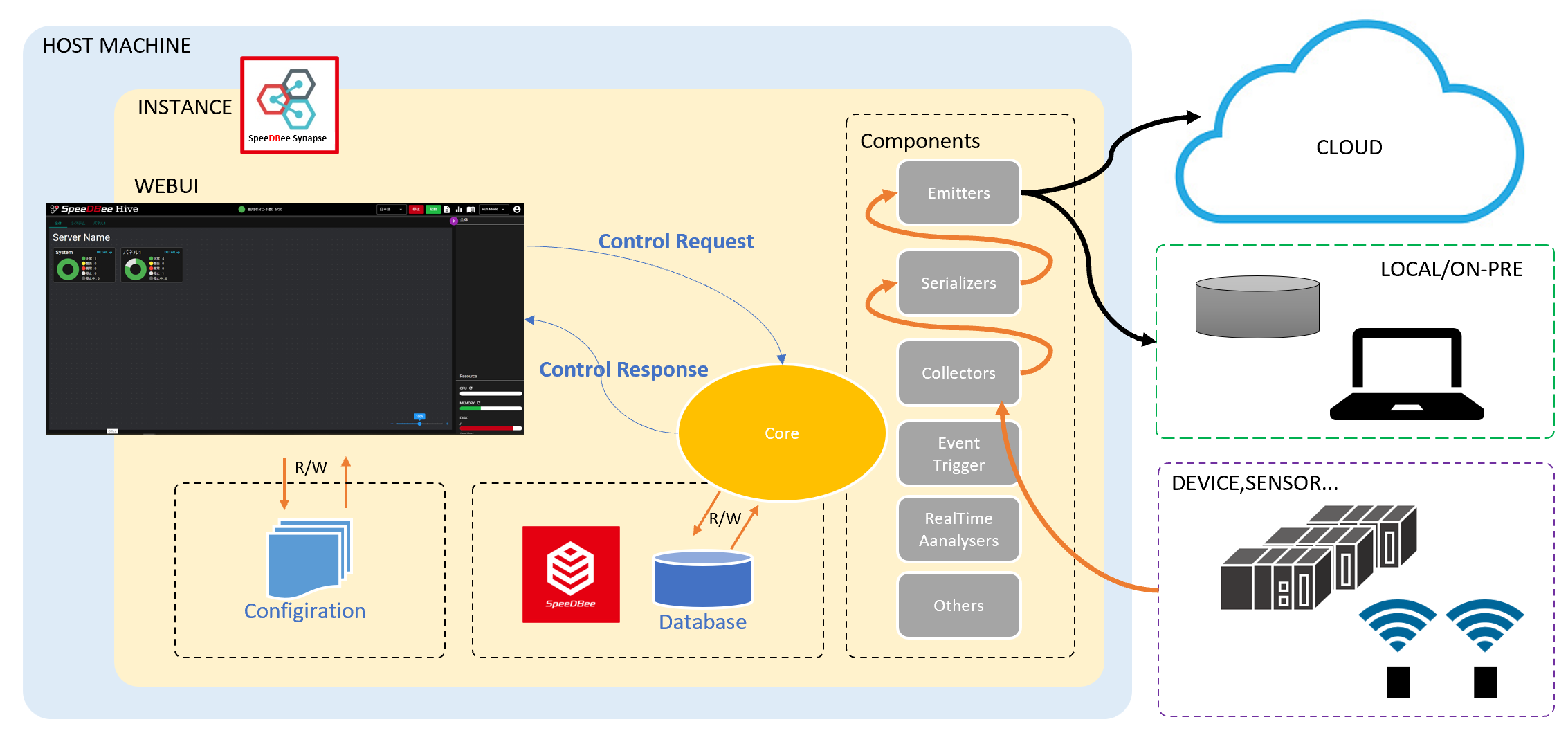
2.2 SpeeDBee Synapseの構成#
SpeeDBee Synapseは、大きく4つの機能により構成されます。
| 機能名 | 説明 |
|---|---|
| コア | 収集エンジンの全体機能を制御する中心部です。 |
| コンポーネント | データの収集、加工、分析、送信などを実現するモジュール群です。 コンポーネント間を接続することで様々な機能が実現できます。 |
| 時系列データベース | 収集したデータを時間に沿って保存するデータベースです。 |
| WEBUI | 各種機能の設定、データの可視化をするユーザーインターフェースです。 |
コンポーネントは8つのカテゴリで分類されます。 各カテゴリに属するコンポーネントを下表に示します。
| カテゴリ | 名称 | 説明 |
|---|---|---|
| コレクタ | - | データ収集機能を提供します。データ収集後の各種機能を利用するための起点となります。 |
| EtherNet/IP | EtherNet/IP対応機器からデータ収集します。 | |
| PLC | PLCのレジスタ/変数情報からデータ収集します。 | |
| Modbus | Modbus対応機器からデータ収集します。 | |
| MQTT | MQTTプロトコル(Subscribe)によるデータ収集を行います。 | |
| リソース | 稼働マシン内のシステムリソース(CPU使用率、メモリ消費など)を収集します。 | |
| 演算コレクタ | 収集データを使った演算の結果を新しい別データとして登録します。 | |
| エミッタ | - | データ出力またはデータ送信機能を提供します。外部システムとの連携に活用できます。 |
| Cloud(Azure用) | Azure IoT Hub向けにデータ送信を行います。 | |
| MQTT | MQTTプロトコル(Publish)によるデータ送信を行います。 | |
| FTP/FTPS/SFTP | FTP、FTPSまたはSFTPによるデータ転送を行います。 | |
| File | 収集したデータをファイルとして、ストレージへ保存します。 | |
| Cloud(AWS用) | AWS IoT Core向けにデータ送信を行います。 | |
| シリアライザ | - | データを指定フォーマットへ加工します。 |
| CSV | 指定データをCSV形式へ加工します。 | |
| JSON | 指定データをJSON形式へ加工します。 | |
| デシリアライザ | - | 指定フォーマットをデータへ加工します。 |
| JSON | JSON形式の指定データを加工します。 | |
| アクション | - | 収集したデータを使った任意のアクションを提供します。 |
| シェルコマンド | 収集したデータを使った任意のシェルコマンドを実行します。 | |
| メール送信 | 収集したデータを使ってメール送信を行います。 | |
| Modbus書き込み | Modbus対応機器の指定アドレスへ値を書き込みます。 | |
| PLC書き込み | PLCの指定アドレスへ値を書き込みます。 | |
| EtherNet/IP書き込み | EtherNet/IP対応機器へ値を書き込みます。 | |
| ロジック | - | リアルタイム分析や収集データの判定処理を提供します。 |
| イベントデータ | 収集したデータを条件判定し、条件合致した場合のみ、新たに別データとして登録します。 | |
| イベントトリガ | 収集したデータを条件判定し、条件合致している区間の情報提供を行います。 | |
| 基本統計 | 収集データを用いて統計処理した結果を別データとして登録します。 | |
| 移動平均 | 収集データの移動平均値をデータとして登録します。 | |
| FFT | 収集データのFFTした結果をデータとして登録します。(周波数、強度) | |
| システム | - | システムに関連する機能を提供します。 |
| DBクエリサービス | SpeeDBee Synapse内で集めたデータへの問い合わせが可能です。Grafana連携でも使用します。 | |
| コアインターナル | SpeeDBee Synapse内の内部ステータスを管理するコンポーネントです。 | |
| エラーマネージャー | SpeeDBee Synapse内で発生した全エラーを検知できるコンポーネントです。 | |
| カスタム | - | ユーザーがPythonまたはC言語で設計したプログラムで構成されたコンポーネントです。標準のコンポーネントでは出来ない様々な機能を追加できます。 |
2.3 運用までの流れ#
SpeeDBee Synapseの運用までの基本的な流れは、次の通りです。
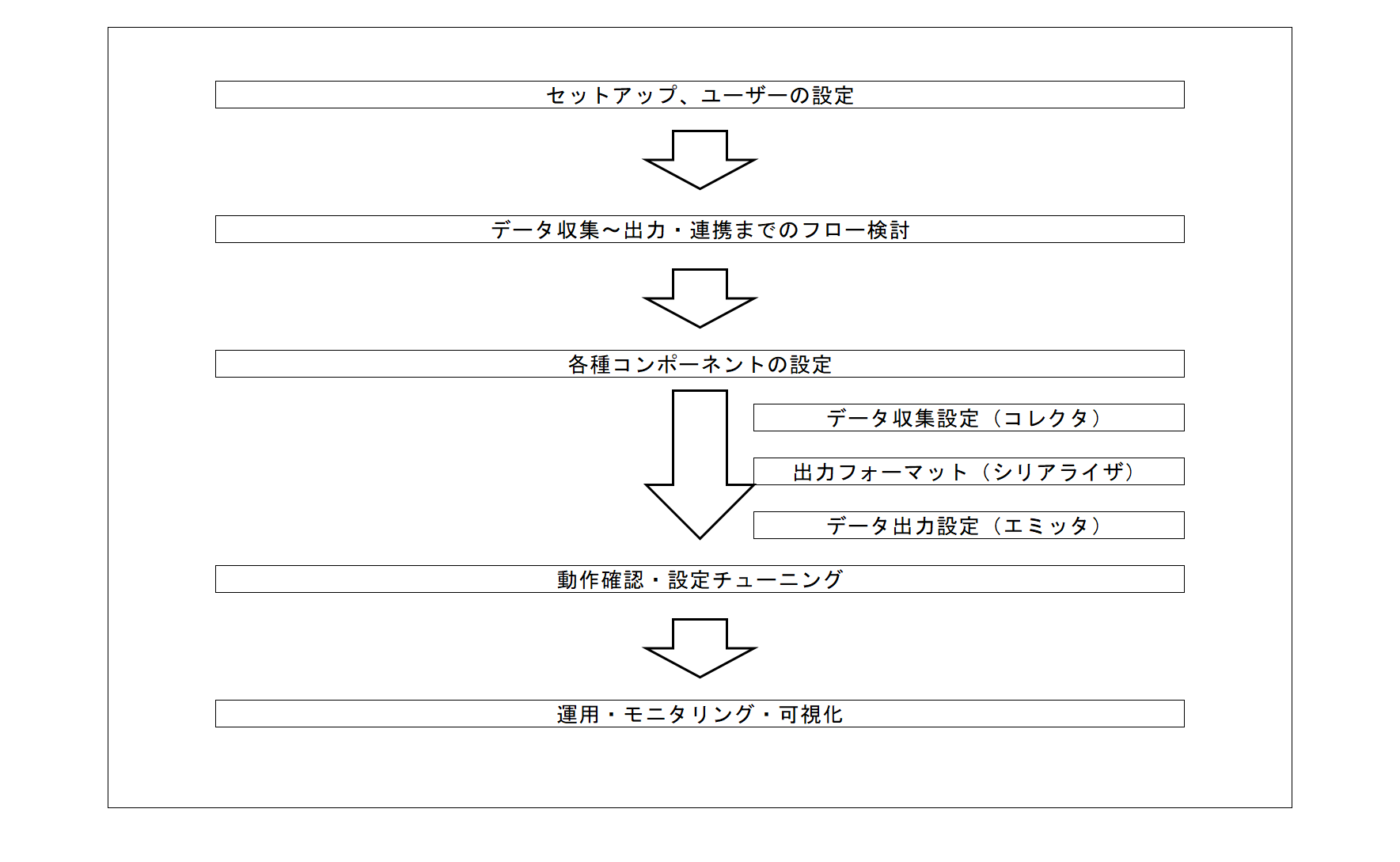
①セットアップ・ユーザーの設定
本マニュアルを参考に、SpeeDBee Synapseのセットアップを行います。 また、利用者の権限に応じたユーザーを設定します。
②データ収集~出力・連携までのフロー検討
システムの目的に応じて、実際に、何のデータを収集するか、使用する機器の選定・検討を行います。 また、集めたデータを最終的に、どのような形式で出力して活用するかを設計します。 利用するコレクタ、シリアライザ、エミッタなど対応機能を確認します。 この段階で、サポートしていないプロトコルなどが必要な場合は、カスタムコンポーネントの開発も視野に検討します。
③各種コンポーネントの設定
検討したフローに従って、各種コンポーネントの設定を行います。 基本的な流れとしては、データ収集、加工、出力の順で設定していきます。
- データ収集設定(コレクタ)
データ収集の設定を行います。収集元の機器やその設定が正しい事を確認します。 その後、実際にコンポーネントの設定を行います。
- 出力フォーマットの設定(シリアライザ)
データの出力形式の設定を行います。CSVやJSONのいずれかを設定します。 また、出力ファイルをどのような単位で分割するかなどもここで設定します。
- データ出力設定(エミッタ)
出力したデータを最終的にどのように処理するかを設定します。 例えば、Fileエミッタでは、出力ファイルをストレージへ保存するため、その保存先の設定などを行います。 外部へのデータ送信を行う場合は、外部の接続に必要な情報を確認して設定を行います。
④動作確認・設定チューニング
設定した各コンポーネントが正しく動作しているか確認します。正常にデータ収集できている事、指定した形式でのデータ出力および 送信ができている事を確認します。意図していない動作などあれば設定を見直して、設定変更、再確認を行います。
⑤運用・モニタリング・可視化
実際にシステムを運用します。データ活用エンジンの提供する機能を使い、データのモニタリングやグラフの可視化ができます。 運用中に問題が生じた場合は、再検討を行い設定チューニングを再実施して下さい。
この他に、目的に応じて、リアルタイム分析やイベント連携などの設定を行う事で、SpeeDBee Synapseを活用したシステムが構築できます。