14. Pythonカスタムコレクタ#
14.1 カスタムコレクタとは#
SpeeDBee Hiveでは、データの収集を行うモジュールのことを"コレクタ"と呼びます。
標準ではPLC等のデータを収集する"コレクタ"が用意されていますが、
ユーザーが独自にコレクタを開発、運用することも可能です。
コレクタの開発にはC言語、もしくは Pythonを使用できます。
本ドキュメントではPythonによるカスタムコレクタの開発 方法を説明します。
14.1.1 対象読者と前提知識#
本書は、SpeeDBee Hiveを使用する上で、Python言語を用いて独自のコレクタを開発することを目的とするユーザーを対象としています。
本書を読む上での前提知識として、Python言語のチュートリアルの内容は大方把握できていること、
併せてクラス定義、メソッド定義、クラスの継承等について理解していることを想定しています。
入門レベルの情報については、下記の Python公式ドキュメントを参照してください。
Python公式ドキュメント: https://docs.python.org/ja/3/
14.1.2 Pythonカスタムコレクタの実行環境#
本書で説明するPythonカスタムコレクタは、SpeeDBee Hiveをインストールした環境により実行するPythonバージョンが異なります。
| プラットフォーム | Pythonバージョン |
|---|---|
| Windows | 3.9.6 |
| Linux:Ubuntu18 | 3.6.9 |
| Linux:Ubuntu20 | 3.8.10 |
| Linux:Ubuntu22(Arm64) | 3.10.12 |
| Linux:Raspberry Pi(buster) | 3.7.3 |
| Linux:Raspberry Pi(bullseye) | 3.9.2 |
| Linux:BlackBear | 3.5.3 |
実際のバージョンについては実行環境でも確認可能です。 カスタムコレクタ登録の画面の最下部から確認してください。
14.1.3 制限事項#
現バージョンにおいて、Pythonカスタムコレクタには以下の制限事項があります。ご注意ください。
- RaspberryPi環境において、オプションコレクタの OCRコレクタ(カメラ画像からテキストを抽出)とは同時に利用できない
14.2 Pythonカスタムコレクタのサンプル#
カスタムコレクタの作り方の説明のため、単純なデータ収集を行うシンプルなカスタムコレクタをサンプルとして提供しています。 SpeeDBee Hive Web画面の下記より、参照、もしくはダウンロードが可能です。
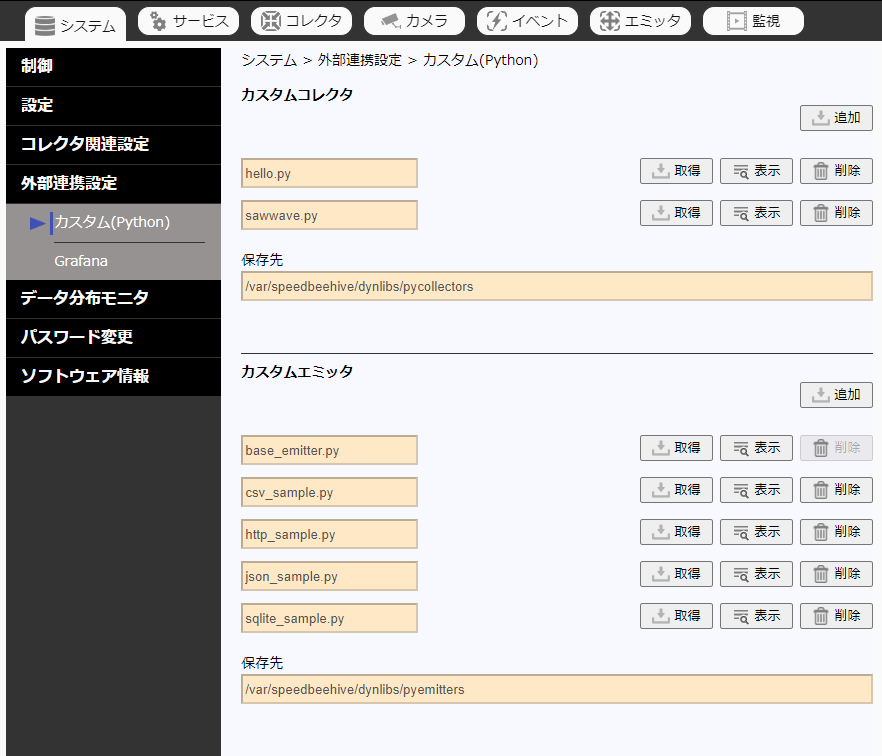
14.2.1 Pythonカスタムコレクタのサンプル内容#
Python カスタムコレクタのサンプルとして2つのコレクタを提供しています。 それぞれ特に実用的なものではありませんので、あくまでサンプルとして参照してください。
- sawwave.py
1つのデータ系列に対して1~100までの値を順に登録する動作を繰り返すコレクタ。 - hello.py
データ分布モニタで表示した際に「HELLO」の文字が見えるように5つのデータを登録し続けるコレクタ。
14.2.2 利用設定#
カスタムコレクタを利用する場合、Web画面から設定します。 ここではサンプルとして提供されているhello.pyを利用する手順を説明します。
14.2.2.1 カスタムコレクタ設定#
すでに登録済みのPythonカスタムコレクタを利用する場合は下記の手順で設定してください。
-
サブメニュー「カスタム」の
 をクリックすると新規登録画面が表示されます。
をクリックすると新規登録画面が表示されます。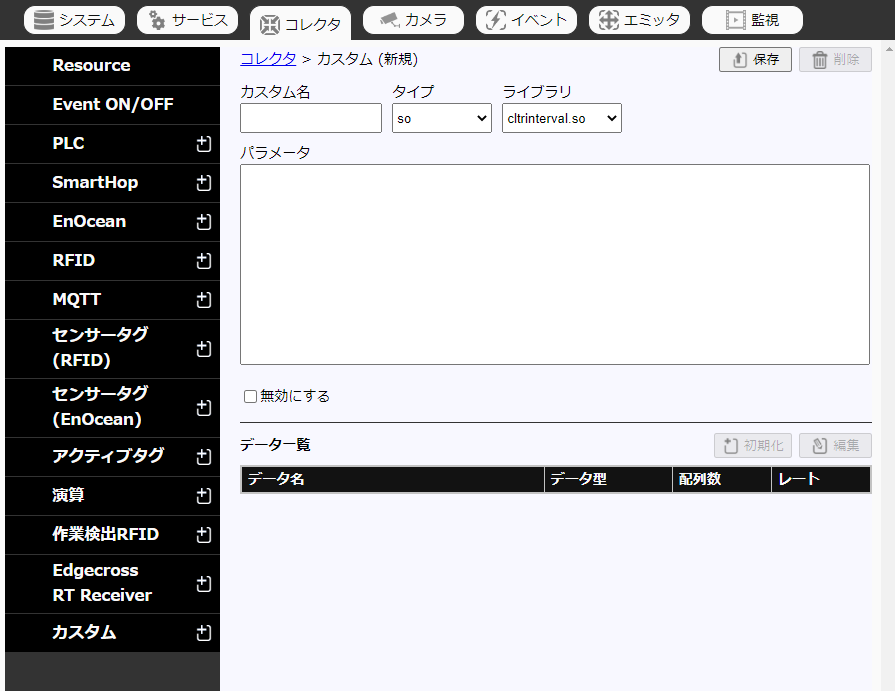
-
各項目を入力し、「保存」をクリックし設定を保存します。
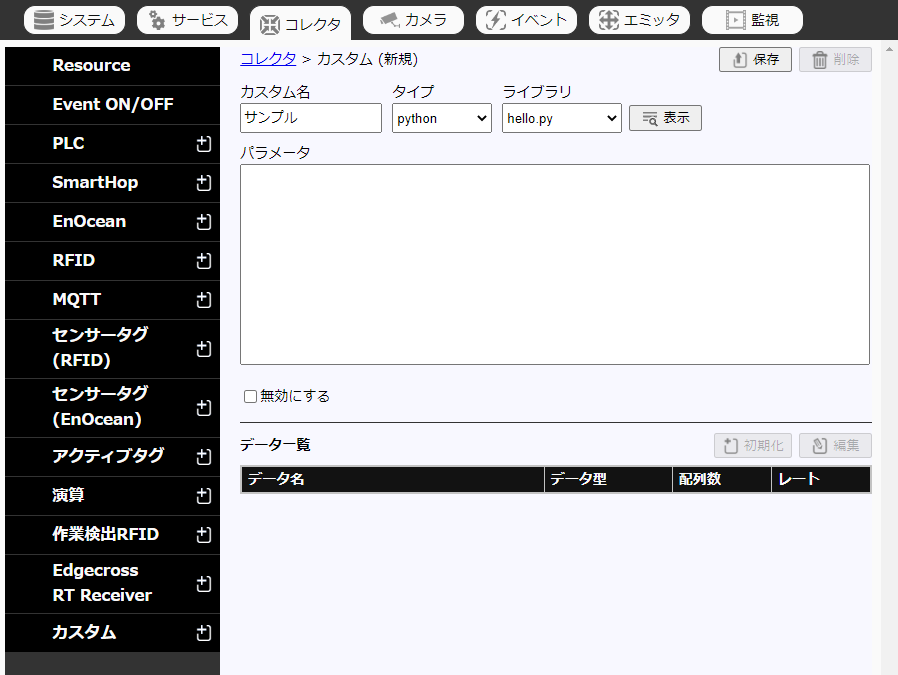
設定が必要な項目は以下の通りです
入力項目 説明 カスタム名 データを収集するコレクタ名 ※コレクタ全体で重複不可 タイプ カスタムコレクタ(Python)を使用する場合はpythonを選択 ライブラリ 使用するカスタムコレクタ(Python)のスクリプトファイル名
表示ボタンを押下すると、スクリプトの内容を確認できます。
※保存後は変更不可パラメータ スクリプト内で利用される引数(文字列)
hello.pyでは入力の必要はありませんが、独自に作成したPythonスクリプト内でパラメータを使用する場合には、こちらに入力してください。 -
保存後に「初期化」をクリックすると使用するデータ一覧が表示され、実行する準備が整います。
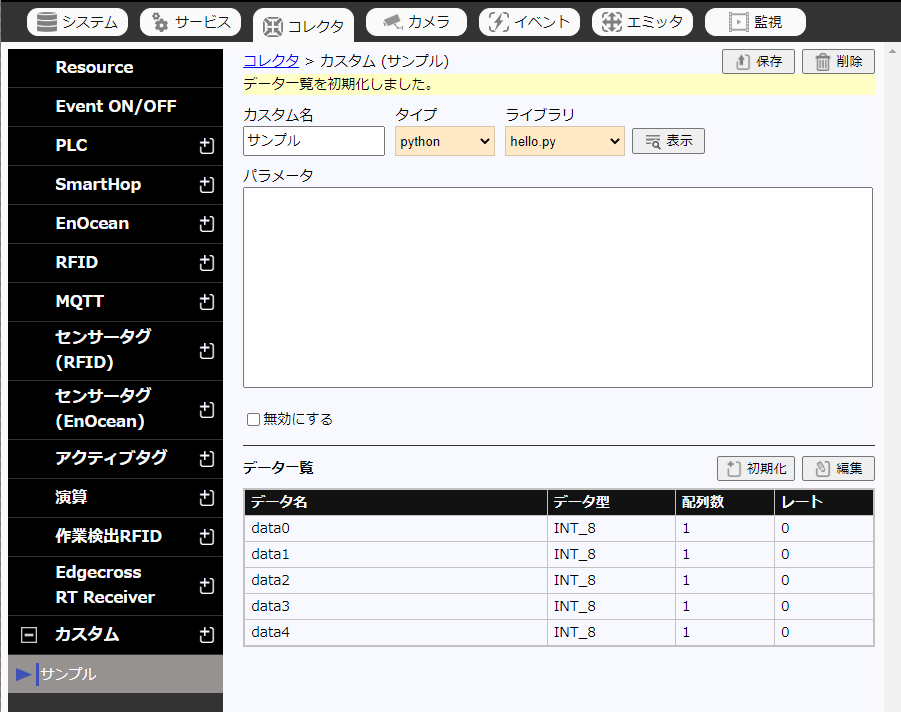
-
その後、「システム」タブの「制御」にてHiveを再起動するとhello.pyカスタムコレクタが実行されます。
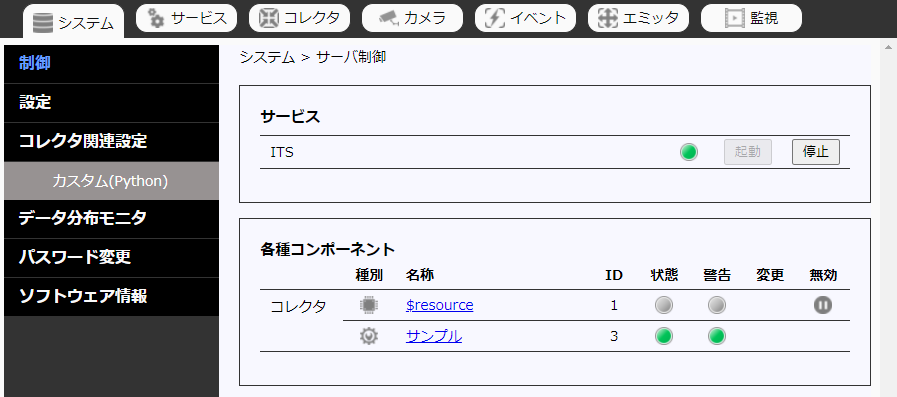
-
カスタムコレクタが登録したデータの内容はデータ分布モニタで確認できます。
「システム」>「データ分布モニタ」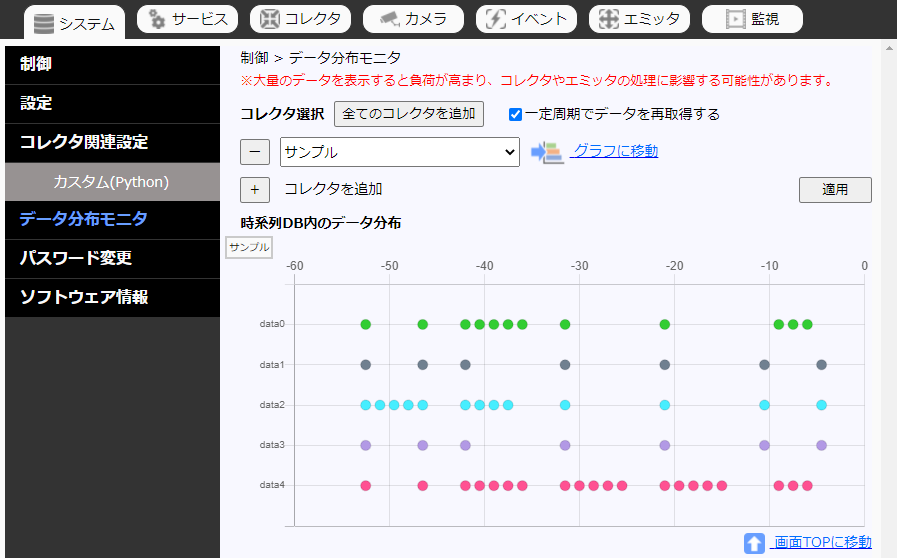
14.2.2.2 データ編集#
カスタムコレクタを利用する場合も、他のコレクタ同様、 各データに対して数値変換や登録条件を付けることが可能です。下記の手順で行ってください。
-
カスタムコレクタの設定画面にて、データ一覧の「編集」をクリックし、データ編集画面に移動します。
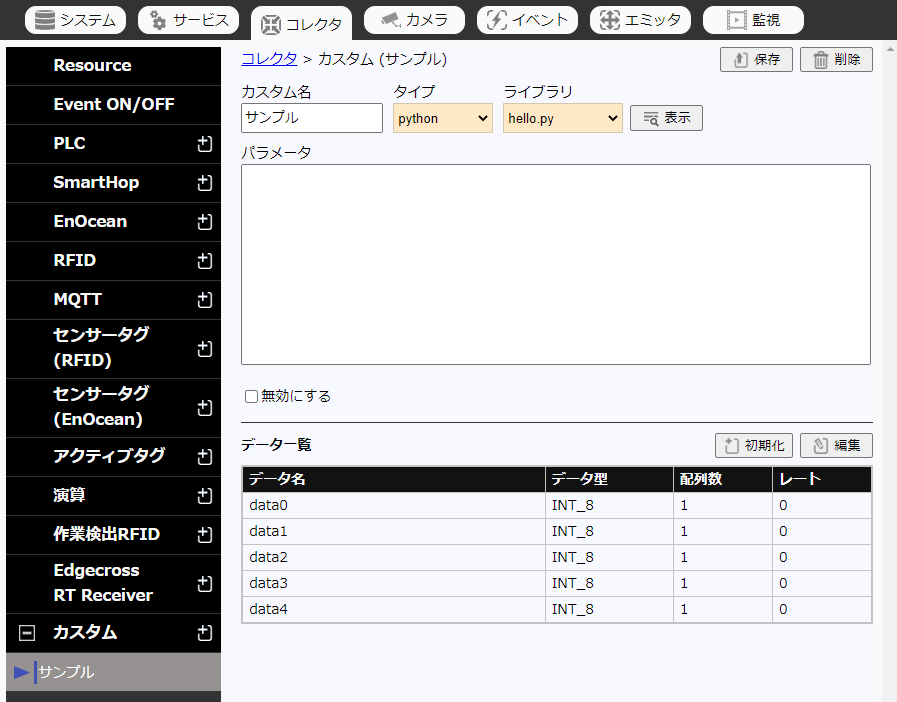
-
ページ下部にあるデータ一覧から、設定編集したいデータをクリックし選択します。
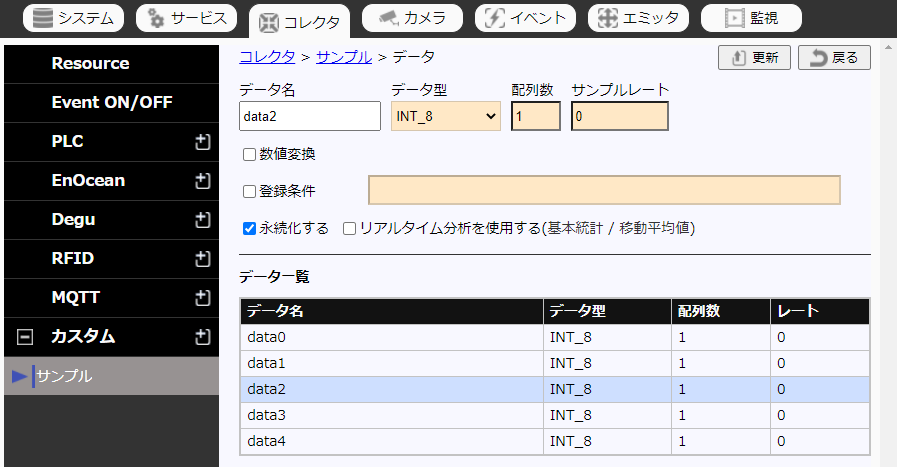
-
この画面にて、以下の設定変更が可能です。編集後は「更新」をクリックしてください。
変更が可能な項目は以下の通りです
入力項目 説明 データ名 データ名称 ※コレクタ内で重複不可 数値変換 コレクタが取得した値を指定した計算式で変換し登録する 登録条件 コレクタが取得した値を指定した条件式で判定し、条件が真となる場合のみ登録する 永続化する ストレージ上に保存する リアルタイム分析を使用する リアルタイム分析を利用する
チェック時には基本統計、移動平均、FFTをクリックすることで編集画面を表示(詳細は「ユーザーガイドの補足」を参照)
※FFT はサンプルレートが 1 以上の場合のみ選択可能数値変換、登録条件については「ユーザーガイドのコレクタの共通機能」を参照してください。 リアルタイム分析については「ユーザーガイドのリアルタイム分析について」を参照してください。
14.2.2.3 カスタムコレクタ登録#
独自にPython カスタムコレクタを開発した場合、下記の手順で登録してください。
-
「システム」タブ→「外部連携設定」→「カスタム(Python)」より、Pythonカスタム管理画面を開きます。
-
「カスタムコレクタ」欄の「追加」をクリックし、開発したPythonカスタムコレクタを選択、「開く」をクリックします。
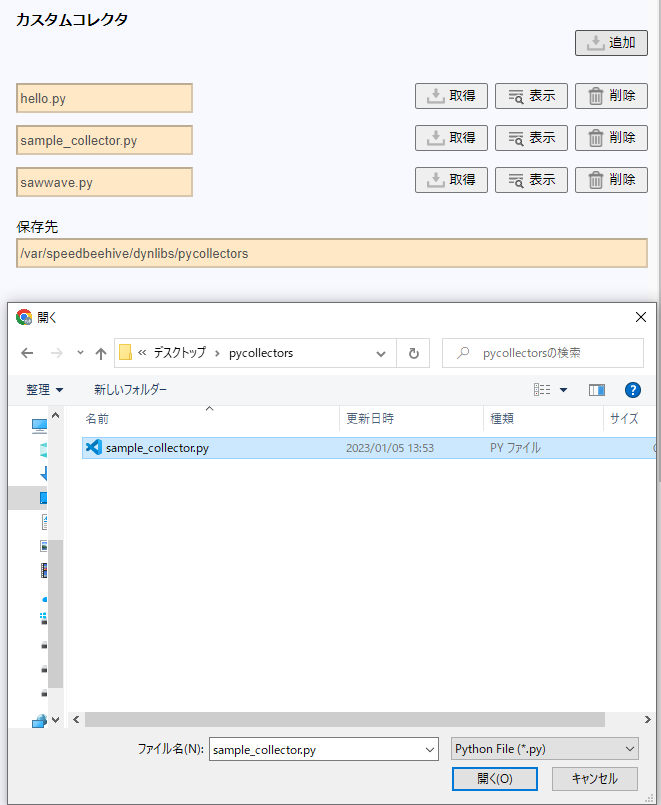
-
登録が完了するとカスタムコレクタの一覧に表示されます。
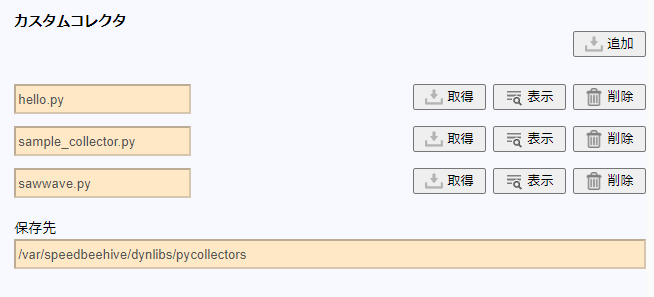
この後は、「2.2.1 カスタムコレクタ設定」の手順によりカスタムコレクタを実行することができます。
同一名称のコレクタがすでに登録されていた場合は上書きされます。 削除する場合は上記の画面から該当コレクタの「削除」をクリックしてください。
Python カスタムコレクタでは、初期状態でも Python の標準モジュールを使用可能ですが、 もし標準モジュールではなく、外部モジュールを利用したい場合は、この画面からインストールを行ってください。
-
Pythonモジュールのテキスト欄に使用するモジュール名を入力し「追加」をクリックします。
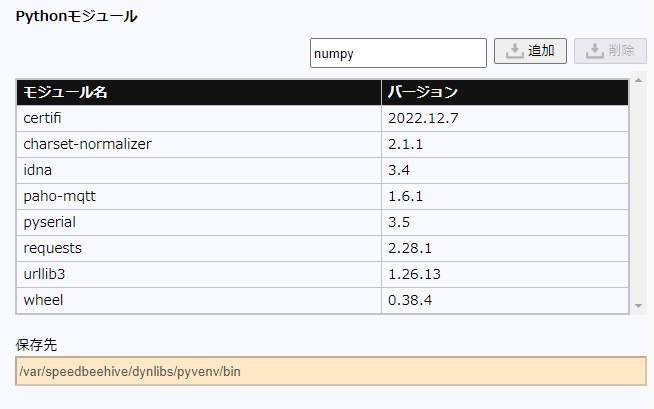
-
ダイアログにて「OK」をクリックします。
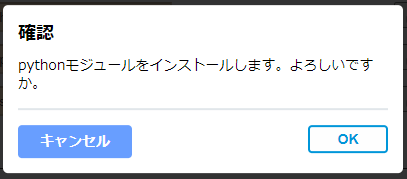
-
インストールが完了すると、インストールされたモジュールが一覧されます。
指定したモジュール以外にも依存するモジュールが自動で登録されます。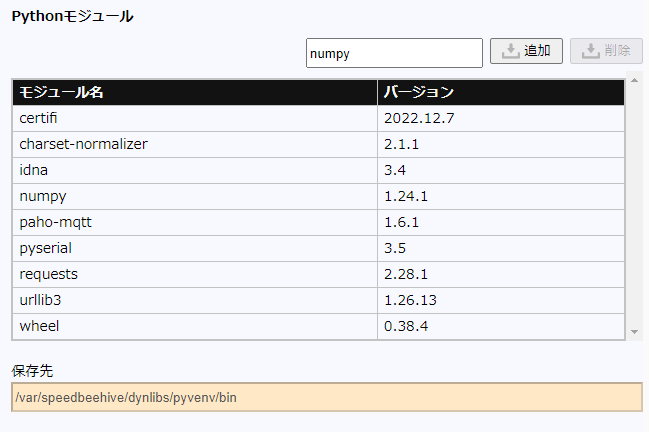
Note
指定したモジュールに加え、その依存モジュールも自動的にインストールされます。
モジュールのインストールに長時間かかる場合や、
そのモジュールを実行するために必要なライブラリがインストールされていない場合など、
様々な要因でインストールに失敗する可能性があります。
もしこの画面からPythonモジュールのインストールに失敗する場合は、
SpeeDBee Hiveの動作するデバイスにログインし直接pipコマンドでインストールしてください。
$ sudo /var/speedbeehive/dynlibs/pyvenv/bin/pip3 install {モジュール名}
PS> C:\ProgramData\SALTYSTER\SpeeDBeeHive\dynlibs\pyvenv\Scripts\pip3.exe install {モジュール名}
14.3 カスタムコレクタのソースコードの説明#
この節ではPythonカスタムコレクタサンプルのsawwave.pyをもとにカスタムコレクタの作りについて説明します。 このソースコードもカスタムコレクタ(Python)管理画面から取得可能です。
from hive_collector import HiveCollectorBase, HiveColumn
class HiveCollector(HiveCollectorBase):
def __init__(self, param):
self.logger.info("init")
self.count = 1
self.max = 100
self.clm0 = self.makeOutputColumn("data0", HiveColumn.TypeInt8)
def mainloop(self):
self.logger.debug("main loop execute")
self.intervalCall(int(0.5*1000*1000), self.proc)
def proc(self, ts, skip):
self.clm0.insert(self.count)
self.count += 1
if self.count > self.max:
self.count = 1
14.3.1 専用モジュールのインポート#
Pythonカスタムコレクタを開発する際にはかならずHiveCollectorBaseクラスと HiveColumnクラスをインポートする必要があります。
from hive_collector import HiveCollectorBase, HiveColumn
14.3.2 コレクタクラス定義#
Pythonカスタムコレクタでは、HiveCollectorBaseクラスを継承したHiveCollectorという名称のクラスを、
スクリプトファイル内で必ず定義する必要があります。
下記がその定義概要です。(各メソッドの詳細は後述)
class HiveCollector(HiveCollectorBase):
def __init__(self, param): # コレクタのコンストラクタ
:
def mainloop(self): # コレクタのメインループ
:
def proc(self, skip, ts): # コレクタの定期処理
:
14.3.3 コンストラクタ#
コレクタの開始時に最初に実行されるメソッド(HiveCollector.__init__)です。
引数として自分自身のインスタンスと"param"を受け取っています。
paramはWeb UIでパラメータとして定義した文字列、もしくはNoneになります。
パラメータを受け取って動作を変える必要がある場合はparamを参照してください。
また、コンストラクタ内でself.makeOutputColumn()メソッドをコールすることにより、
コレクタが出力するデータを登録する”カラム”を定義することができます。
class HiveCollector(HiveCollectorBase):
def __init__(self, param):
self.logger.info("init")
self.count = 1
self.max = 100
self.clm0 = self.makeOutputColumn("data0", HiveColumn.TypeInt8)
:
14.3.4 メインループ#
カスタムコレクタのデータ収集のメイン処理を記述するメソッド(HiveCollector.mainloop)です。 コレクタが開始されると、コンストラクタの後にこの関数が呼ばれます。この関数が終了すると、 コレクタとしても動作終了となります。
サンプルでは、単純にself.intervalCall()を呼び出しています。 これにより、引数に与えられたproc関数が定期的(サンプルでは 0.5 秒間隔)にコールされ、 コレクタの終了通知が来ると自動的に終了します。
class HiveCollector(HiveCollectorBase):
:
def mainloop(self):
self.logger.debug("main loop execute")
self.intervalCall(int(0.5*1000*1000), self.proc)
:
下記のprocは、self.intervalCall()の内部から、定期的にコールされる関数です。
ここで1周期分のデータを収集し、SpeeDBee Hiveに登録しています。
このサンプルでは、特に外部からデータを取得するわけではなく、
内部的に計算した結果をデータとして登録しています。
class HiveCollector(HiveCollectorBase):
:
def proc(self, ts, skip):
self.clm0.insert(self.count)
self.count += 1
if self.count > self.max:
self.count = 1
‘self.clm0.insert()’が実際にデータを登録するメソッドです。 ここでは self.count の値をカラム’clm0’に登録しています。 上記実装の通り、proc が 0.5 秒間隔で呼び出されるたびに、 self.countは1~100の範囲で変動し、その値がこのコレクタの出力として登録されます。
14.4 カスタムコレクタ内で利用可能なクラス#
Pythonカスタムコレクタのスクリプト内で使用可能なクラス等について説明致します。
14.4.1 HiveCollectorクラス#
Pythonカスタムコレクタのスクリプトにて定義する必要があるクラスです。 必ずHiveCollectorBaseクラスを継承して定義する必要があります。 クラスの定義内容はPythonカスタムコレクタ実装者の任意ですが、 Hiveから呼び出される特殊な関数が2つあり、この2つは定義が必須です。 詳細は以降の説明を参照してください。 このクラス内からはHiveCollectorBase内のメソッドを使用することができます。
14.4.1.1 init() … 初期化#
コレクタ開始時に、自動的に呼び出されるコンストラクタです。 Pythonカスタムコレクタの実装者はこれを定義する必要があります。
書式
hivecollector.__init__(self, param)
引数
| No. | 引数 | 説明 |
|---|---|---|
| 1 | self | HiveCollectorのインスタンス __init__実行後、他のメソッドでも共有する必要のある情報はself内のプロパティとして追加してください。 (例)sawwave.pyのself.count |
| 2 | param | パラメータ文字列 このPythonコレクタを実行する上で、設定画面にて登録したパラメータが文字列としてこの引数に渡されます。 この使用方法は特に決まりはありませんので、実装するコレクタの内容に合わせて適宜参照してください。 |
戻り値
- なし
説明
コレクタ開始時に、自動的に呼び出されるコンストラクタです。
このメソッドが呼び出されることでコレクタに指定されたパラメータ文字列を受け取ることができます。
また、コレクタが収集したデータを登録するためのカラムはこのメソッド内で定義する必要があります。
カラムの作成にはHiveCollectorBase.makeOutputColumnメソッドを使用してください。
本メソッドが例外を送出する場合、コレクタは実行されません。パラメータの不備や環境不備
等で、以降のmainloop処理が実行できない場合は、下記のように例外を送出してください。
class HiveCollector(HiveCollectorBase):
def __init__(self, param):
:
if self.check_problem():
raise Exception(“some error message”)
14.4.1.2 mainloop() … メインループ#
コレクタにおける主たるデータの収集処理を定義するためのメソッドです。 Pythonカスタムコレクタの実装者はこれを定義する必要があります。
書式
hivecollector.mainloop(self)
引数
| No. | 引数 | 説明 |
|---|---|---|
| 1 | self | HiveCollectorのインスタンス __init__で保持したプロパティ等を参照するために利用してください。 (例)sawwave.py の self.count |
戻り値
- なし
説明
コレクタ開始時、__init__の後で自動的に呼び出されるメソッドです。
__init__にて作成したカラムに対して、このメソッド内で登録処理を行うことで、
データをHiveに送ることができます。
このメソッドが例外を送出した場合、コレクタの動作は停止します。これ以上処理を継続でき
ないようなエラーが発生した場合には例外を送出してください。逆に、何らかの例外発生時に
もコレクタを停止させたくない場合は、try-exceptで例外をキャッチする必要があります。
実装例
一定間隔で何らかの処理を実行してデータを登録する場合は、 下記のようにHiveCollectorBase.intervalCall()の使用が推奨されます。
class HiveCollector(HiveCollectorBase):
:
def mainloop(self):
self.intervalCall(int(0.5*1000*1000), self.proc)
def proc(self, ts, skip):
data = self.compute_some_data()
self.clm0.insert(data)
不定期になんらかのデータを受信して登録するような場合は、下記のような単純なループで実装可能です。 ただしHiveから停止通知が来ていないか常にチェックする必要があります。
class HiveCollector(HiveCollectorBase):
:
def mainloop(self):
while self.runnable(): # システムから停止通知が来ていないかチェック
try:
data = self.receive_some_data(timeout=5.0) # データを受信(タイムアウト必須)
self.clm0.insert(data)
except TimeoutExpired:
pass
14.4.2 HiveCollectorBaseクラス#
Pythonカスタムコレクタを定義するベースとなるクラスです。 HiveCollector内で使用するための様々な関数を用意しています。
14.4.2.1 makeOutputColumn() … カラム作成#
コレクタが出力するデータを登録する”カラム”を作成するメソッドです。 HiveCollectorの__init__内でのみ使用可能です。
書式
hivecollectorbase.makeOutputColumn(name, type, arraySize=0)
引数
| No. | 引数 | 説明 |
|---|---|---|
| 1 | name | 作成するカラムの名前を指定する文字列 ここで指定した文字列がデフォルトでのデータの名前となりますが、設定画面にて変更することも可能です。 |
| 2 | type | 作成するカラムの型 使用可能な型については説明欄を参照してください。 |
| 3 | arraySize | 作成するカラムの配列要素数(省略可) 配列カラムの場合は 1 以上の整数を指定してください。省略時、0指定時はスカラ型として扱われます。 |
戻り値
- HiveColumnクラス
説明
コレクタがデータを登録するためのカラムを作成するメソッドです。
HiveCollectorBaseを継承したHiveCollectorの__ini__コンストラクタ内でのみ使用可能です。
typeには「TypeXxxx … 型定義値」で定義されたクラス変数を使用してください。
例) makeOutputColumn(“data0”, HiveColumn.TypeFloat)
arraySize に 1 以上の整数を指定することで、指定された数の要素数を持つ配列型とすることができます。
(省略時、もしくは 0 で非配列型)。
この場合、カラムにデータを登録する際には配列要素数分のデータをまとめて登録する形になります。
ただし、TypeString、TypeBinaryでは配列型は使用できません。
14.4.2.2 intervalCall() … 定期処理実行#
HiveCollectorのmainloop にて、指定した関数を定期的に実行するためのメソッドです。
書式
hivecollectorbase.intervalCall(interval, callback)
引数
| No. | 引数 | 説明 |
|---|---|---|
| 1 | interval | 実行間隔(usec単位) func を呼び出す間隔をマイクロ秒単位で指定します。1以上の整数を指定してください。 |
| 2 | callback | 実行関数 定期的に実行する関数を指定します。 指定された関数は、2つの引数を受け取る必要があります。 |
戻り値
- なし
説明
HiveCollector の mainloop にて、指定した関数、もしくはメソッドの処理を、
一定間隔で実行するために呼び出すメソッドです。
このメソッドは、Hiveが終了するまではintervalで指定された間隔で延々とcallbackを呼び出し続けます。
callbackに指定する関数の形式については下記を参照してください。
intervalに指定した時間幅より、callback の処理時間が長くなってしまった場合、
定期的な処
理が実行できないため、スキップされる可能性があります。
もしスキップされた場合、その次のcallbackの実行時にスキップされた数が引数skipにて通知されます。
intervalが小さすぎると、システムの負荷が高まりその他のコレクタやエミッタの処理に
影響を与える可能性がありますのでご注意ください。
callbackの詳細
書式
callback(skip, timestamp)
引数
| No. | 引数 | 説明 |
|---|---|---|
| 1 | skip | スキップカウント callbackの定期処理が追いつかず、予定したタイミングの処理がスキップされた場合にそのスキップされた数が渡されます。正常なタイミングで処理されていれば常に0となります。 |
| 2 | timestamp | タイムスタンプ このfuncがコールされたときのタイムスタンプです。タイムスタンプの詳細は「getTimestamp() … タイムスタンプ取得」を参照してください。 |
戻り値
- なし
説明
HiveCollectorBase.intervalCallにてcallback引数に指定された関数の書式です。
上記の通り、2つの引数を受け付ける関数としてください。
この関数が例外を送出した場合、その例外はHiveCollectorBase.intervalCallの呼び出し元まで伝達されます。
14.4.2.3 getTimestamp() … タイムスタンプ取得#
現在時刻のタイムスタンプ(ナノ秒単位)を取得する関数です。
書式
hivecollectorbase.getTimestamp()
引数
- なし
戻り値
- 現在時刻を示す整数
説明
現在時刻のタイムスタンプを取得する関数です。タイムスタンプは単純な整数値となっており、
UNIX エポック(1970年1月1日0時0分0秒(UTC))を0としたときの経過ナノ秒数で表現されています。
例)
| 引数 | 説明 |
|---|---|
| 1970年1月1日0時0分0秒.0(UTC)1 | 0 |
| 1970年1月1日9時0分0秒.0(JST) | 0 |
| 1970年1月1日9時0分1 秒.0(JST) | 1000000000 |
| 1970年1月1日9時1分0 秒.0(JST) | 60000000000 |
| 1970年1月1日10時0分0秒.0(JST) | 3600000000000 |
| 2022年1月31日13時0分0秒.0(JST) | 1643688000000000000 |
| 2022年1月31日13時0分1秒.0(JST) | 1643688001000000000 |
| 2022年1月31日13時1分0秒.0(JST) | 1643688060000000000 |
| 2022年1月31日14時0分0秒.0(JST) | 1643691600000000000 |
14.4.2.4 runnable() … コレクタ実行可否確認#
コレクタが継続動作可能かどうかを確認します。
書式
hivecollectorbase.runnable()
引数
- なし
戻り値
- True: コレクタの処理を継続可能
- False: コレクタの処理を継続不可(Hiveから停止通知が来ている)
説明
動作中のコレクタがそのまま継続して動作してよいか、それとも終了するかを判定するためのメソッドです。
コレクタのmainloopでは定期的にこの関数を呼び出して戻り値を確認し、
False となった場合には、不要となったリソースは解放した上で速やかに処理を終了しなければなりません。
intervalCallで定期的な処理を実施している場合は、
その内部で自動的に本関数を呼び出していますので、これを考慮する必要はありません。
14.4.2.5 logger … ログ出力クラス#
コレクタのログを出力するためのHiveLoggerクラスのインスタンスです。
書式
hivecollectorbase.logger
説明
ログを出力するために使用します。 HiveCollectorクラス内からはself.logger.info(“message”)などとして使用してください。
14.4.3 HiveColumnクラス#
HiveCollectorBase.makeOutputColumn()で生成するカラムを表すクラスです。 コレクタからデータをHiveに登録する際はこのクラスに対して操作が必要になります。
14.4.3.1 insert() … データ登録#
カラムに対してデータを登録するメソッドです。
書式
hivecolumn.insert(Data, Timestamp=0)
引数
| No. | 引数 | 説明 |
|---|---|---|
| 1 | Data | 登録するデータ 本カラム作成時(makeOutputColumn呼び出し時)の型に合わせたデータ型を指定してください。 TypeInt/TypeUintなら整数値、 TypeFloat/TypeDoubleは実数値、 TypeStringは文字列を指定可能です。 また、配列型の場合はその配列の要素数と同じサイズのListとする必要があります。 |
| 2 | Timestamp | タイムスタンプ 登録するデータのタイムスタンプを指定します。この引数は省略可能となっており、省略もしくは0を指定した場合は現在時刻が使用されます。 |
戻り値
- なし
説明
カラムに対してデータを登録します。基本的には引数 Timestamp は省略可能です。
もし複数のカラムに同じタイムスタンプで データを登録する必要がある場合は、
事前にHiveCollectorBase.getTimestamp()で時刻を取得し、
その戻り値を引数Timestampに指定することで同一のタイムスタンプにできます。
(そうしない場合、ナノ秒単位で細かなズレが生じます)
1つのカラム内では、登録するデータのタイムスタンプは常に未来に進行していく必要があります。
例えば、12時34分56秒のデータを登録したあとで、巻き戻して12時34分50秒のデータを登録することはできません。
その場合は例外が送出されます。
カラムの型と登録するデータの型の整合が取れない場合や、
タイムスタンプに異常な値が入っている場合などでは例外が送出されます。
使用例)
def __init__(self, param):
self.clm0 = self.makeOutputColumn(“clm0”, HiveColumn.TypeInt32)
self.clm1 = self.makeOutputColumn(“clm1”, HiveColumn.TypeFloat, 3)
self.clm2 = self.makeOutputColumn(“clm2”, HiveColumn.TypeString)
def proc(self, skip, ts):
self.clm0.insert(30) # 整数値の登録
self.clm1.insert([12.34, 56.7, 89.0]) # 浮動小数点数の登録
self.clm2.insert(“some message”) # 文字列の登録
14.4.3.2 insertMultiSamples() … データ登録#
カラムに対して連続する複数のデータを登録するメソッドです。
書式
hivecolumn.insertMultiSamples(Data, Timestamp=0, Timespan=0)
引数
| No. | 引数 | 説明 |
|---|---|---|
| 1 | Data | 登録するデータのリスト リストの各要素は、本カラム作成時(makeOutputColumn呼び出し時)の型に合わせたデータ型を指定してください。 TypeInt, TypeUintなら整数値、 TypeFloat, TypeDoubleは実数値、 TypeString は文字列を指定可能です。 また、配列型の場合はその配列の要素数と同じサイズのListとする必要があります。 |
| 2 | Timestamp | タイムスタンプ 登録するデータのリストのうち、先頭要素のタイムスタンプを指定します。この引数は省略可能となっており、省略もしくは0を指定した場合は現在時刻が使用されます。 |
| 3 | Timespan | 登録時刻間隔(タイムスパン) Dataのリストが2つ以上の要素を持つ場合、各要素の登録時刻の間隔を指定します。 |
戻り値
- なし
説明
カラムに対してデータを登録するところはinsert()と同様ですが、 本メソッドでは同一カラムに対して時間的に連続する複数のサンプルを一括登録できます。 例として、毎秒発生するデータを10秒に一度取得するようなコレクタの場合は、 このメソッドを使うことで10秒分のデータを配列にしてまとめて登録できます。 その他、例外の発生条件等はinsert()と同様です。
使用例)
def __init__(self, param):
self.clm0 = self.makeOutputColumn(“clm0”, HiveColumn.TypeInt32)
self.clm1 = self.makeOutputColumn(“clm1”, HiveColumn.TypeFloat, 3)
self.clm2 = self.makeOutputColumn(“clm2”, HiveColumn.TypeString)
def proc(self, skip, ts):
self.clm0.insertMultiSamples([10,20,30,40],
Timestamp=ts, Timespan=1000000000) # 整数値の登録
self.clm1.inertMultiSamples([[1.2,3.4,5.6],[2.2,6.8,10.2],
Timestamp=ts, Timespan=500000000) # 浮動小数点数の登録
self.clm2.insertMultiSamples(["first","second","third"],
Timestamp=ts, Timespan=333333333) # 文字列の登録
この例の場合、各カラムに登録されるデータは下記のようになります。
clm0:4つのデータ、10,20,30,40 が1秒間隔で登録されます
clm1:2つのデータ、[1.2, 3.4, 5.6]と[2.2, 6.8, 10.2]が500ミリ秒間隔で登録されます
clm2:3つのデータ、"first","second","third"が1/3秒間隔で登録されます
いずれも先頭のデータのタイムスタンプは同時刻[ts]となります。
14.4.3.3 type … カラムの型#
このカラムの生成時に指定した型を表す整数値のインスタンス変数です。
14.4.3.4 arraySize … カラムの要素数#
このカラムの生成時に指定した配列要素数を表す整数値のインスタンス変数です。スカラ(非配列)の場合は0となります。
14.4.3.5 name … カラムの名前#
このカラムの生成時に指定した名前を表す文字列のインスタンス変数です。
14.4.3.6 TypeXxxx … 型定義値#
カラムの型を示す整数値のクラス変数です。以下が定義されています。
| 識別子 | 値 | 説明 |
|---|---|---|
| TypeInt8 | 1 | 8bit符号付き整数 -128~+127の範囲の整数値 |
| TypeInt16 | 2 | 16bit符号付き整数 -32768~+32767の範囲の整数値 |
| TypeInt32 | 3 | 32bit符号付き整数 -2147483648~+2147483647の範囲の整数値 |
| TypeInt64 | 4 | 64bit符号付き整数 -9223372036854775808~+9223372036854775808の範囲の整数値 |
| TypeUint8 | 5 | 8bit符号なし整数 0~+255の範囲の整数値 |
| TypeUint16 | 6 | 16bit符号なし整数 0~+65535の範囲の整数値 |
| TypeUint32 | 7 | 32bit符号なし整数 0~+4294967295の範囲の整数値 |
| TypeUint64 | 8 | 64bit符号なし整数 0~+18446744073709551615の範囲の整数値 |
| TypeFloat | 9 | 単精度浮動小数点数 IEEE754で規定された32bitの浮動小数点数 |
| TypeDouble | 10 | 倍精度浮動小数点数 IEEE754で規定された64bitの浮動小数点数 |
| TypeString | 11 | 255バイトまでの文字列(エンコーディングはASCII or UTF-8に限定) |
| TypeBinary | 13 | バイナリデータ(現時点では使用不可) |
14.4.4 HiveLogger クラス#
Python カスタムコレクタの実行中にログを出力する場合に使用するクラスです。
このクラスはHiveCollectorBaseインスタンスが生成された時点でそのインスタンス変数”logger”
として設定されていますので、このインスタンス変数から利用してください。
14.4.4.1 error(), warning(), info(), debug(), trace() … ログ出力#
コレクタの実行時に何らかのログを残したい場合にこのメソッドを呼び出してください。 メソッド名に応じて出力されるログのレベルが異なります。
書式
hivelogger.error(message)
hivelogger.warning(message)
hivelogger.info(message)
hivelogger.debug(message)
hivelogger.trace(message)
引数
| No. | 引数 | 説明 |
|---|---|---|
| 1 | message | ログ出力する文字列 or オブジェクト 指定した文字列がログファイルに出力されます。文字列以外を指定した場合、そのオブジェクトの__str__メソッドにより取得した文字列をログ出力します。 |
戻り値
- なし
説明
それぞれのメソッドとも、引数に指定した文字列をログに出力します。ただしそれぞれ出力レ ベルが異なるため、Hiveの起動時に設定したログレベルより高いログのみが実際のログファ イルに出力されます。おおよそのログレベルの概念は下表を参考にしてください。
| レベル | 説明 |
|---|---|
| ERROR | 何らかのエラーにより目的が達成できなかった場合に、その原因等を含めて出力するログに使用 |
| WARNING | 目的は達成できるものの設定時の不備やその後の処理に影響が出る可能性があることを出力するログに使用 |
| INFO | 定期的な処理の実行状況など、正常な動作を確認するために出力するログに使用 |
| DEBUG | デバッグ目的などでより詳細な動作状況を確認するために出力するログに使用 |
| TRACE | デバッグ目的などで関数単位の動作をより詳細に確認するために出力するログに使用 |